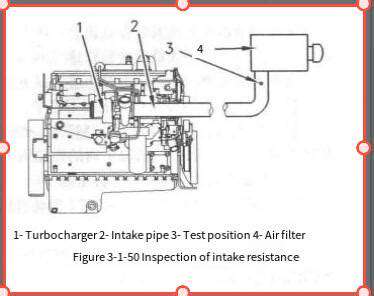
Comprehensive diagnostics for high pressure fuel injection systems
Data Analysis and Troubleshooting Strategies
Understanding Data Analysis
Effective troubleshooting begins with systematic data examination. Analysts must consider data context, quality, and potential biases when drawing conclusions. Key performance indicators (KPIs) serve as vital benchmarks, allowing teams to track system health over time. Proper KPI selection often determines the success of diagnostic efforts.
Historical data analysis helps establish baseline performance levels. Comparing current operations against these benchmarks quickly reveals anomalies that warrant investigation, creating opportunities for proactive maintenance.
Troubleshooting Common Issues
Structured troubleshooting methodologies improve problem resolution efficiency. Latency issues, for example, require systematic investigation of network, database, and application layers. Resource monitoring tools help identify constraints before they impact system performance, allowing preemptive capacity adjustments.
Memory leaks and thread contention represent common challenges in high-performance systems. Detailed logging and real-time monitoring help pinpoint these issues, while automated alerting ensures timely response to critical conditions.
Utilizing Diagnostic Tools
The diagnostic toolkit ranges from simple command-line utilities to enterprise monitoring platforms. Tools like htop provide real-time system resource visibility, while network analyzers like Wireshark decode complex traffic patterns. Database profilers help optimize query performance, often revealing inefficient operations that degrade system responsiveness.
Modern systems increasingly incorporate built-in diagnostic capabilities. These native tools often provide the most direct access to system internals, complementing third-party monitoring solutions.
Data Visualization Techniques
Effective visualization transforms raw data into comprehensible insights. Time-series graphs excel at showing performance trends, while heatmaps reveal usage patterns. Interactive dashboards allow drill-down analysis, helping teams investigate anomalies without switching between multiple tools.
Visual correlation of metrics often reveals unexpected relationships. Combining CPU, memory, and I/O metrics on synchronized timelines can highlight resource contention issues that single-metric views might miss.
Implementing Preventive Measures
Predictive maintenance strategies leverage historical data to forecast future needs. Automated scaling systems adjust resources based on load predictions, maintaining performance during demand spikes. Regular stress testing validates system resilience, ensuring adequate capacity for peak operational scenarios.
Capacity planning processes use trend analysis to anticipate infrastructure requirements. These forward-looking approaches help organizations maintain service levels while optimizing resource utilization.
Case Studies and Real-World Applications

Case Studies: Analyzing Successful Implementations
Examining real-world deployments provides practical insights into technology adoption. Successful implementations often share common characteristics, including thorough planning and stakeholder alignment. These examples demonstrate how organizations overcame challenges to achieve measurable improvements.
Understanding the Context: Project Background and Objectives
Effective case studies clearly articulate the problems being addressed. Well-defined success criteria enable objective evaluation of outcomes, while documenting constraints helps others understand implementation challenges.
Metrics and Evaluation: Quantifying the Impact
Performance metrics should align with business objectives to demonstrate value. Operational efficiency gains often provide the most compelling evidence of success, though quality improvements and risk reduction also contribute significantly.
Challenges and Considerations: Addressing Potential Pitfalls
Implementation challenges offer valuable learning opportunities. Change management issues frequently emerge as significant barriers, while technical integration complexities often require creative solutions.
Lessons Learned and Best Practices: Extracting Key Takeaways
Documented lessons help streamline future projects. Process refinements identified during implementation often yield benefits beyond the immediate project scope.
Future Implications and Recommendations: Anticipating and Adapting
Forward-looking analysis ensures long-term value realization. Scalability considerations become increasingly important as technologies evolve and business needs change.
Read more about Comprehensive diagnostics for high pressure fuel injection systems